Announcing Memory Jogger, relevant email digest for Pocket
I am excited to announce that I recently open sourced Memory Jogger, an app that I built and have been using for the past few months that emails me unread articles and videos I’ve saved.
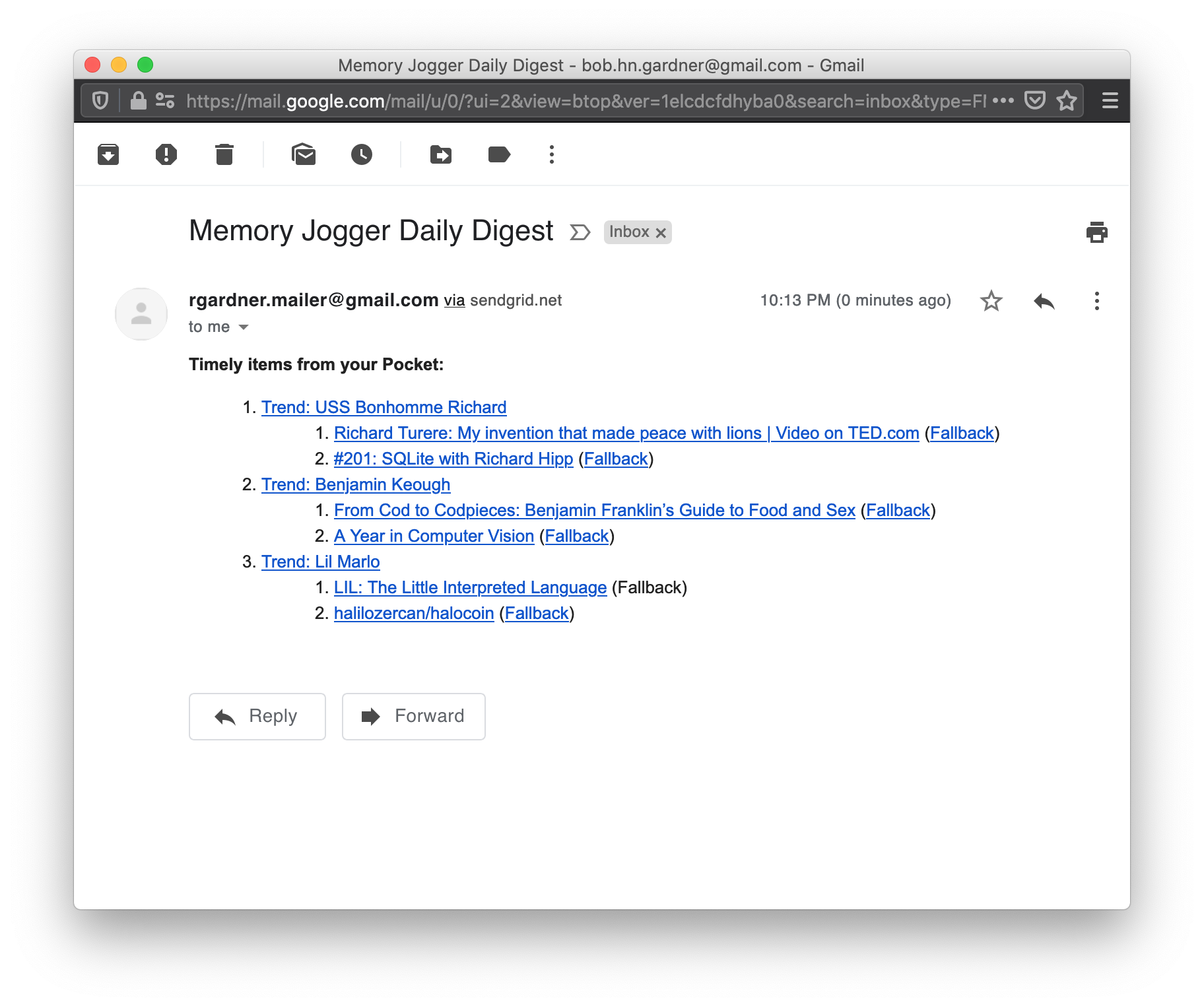
From the README:
Finds items from your Pocket library that are relevant to trending news. I have thousands of unread Pocket items and Memory Jogger enables me to find new meaning in articles and videos I saved years ago. I deployed Memory Jogger to Heroku and set up a daily job to email me unread Pocket items based on Google Trends results from the past two days. Memory Jogger is written in Rust.
I love Pocket and have used it daily since 2013. I typically read news sites or forums such as Hacker News or Reddit, and the original articles and comment sections frequently link to tons of interesting discussions or additional information that I don’t have time for now but want to save for later. As of the time of this writing, I have 5,575 unread items :) I sometimes search these items on-demand, e.g. when researching something for work or fun, but other times I wished there was a way to automatically surface relevant items as an alternative to browsing Hacker News / Reddit. So I built Memory Jogger!
Product Decisions
I’ve had this idea on the back burner for years, but when I started this project in February 2020, I still had questions about how I wanted to use an app like this. I made a couple of key decisions in the beginning:
- email digest as the primary interaction model
- hosted web service with simple UI, available for multiple users to sign up
- Google Trends for determining what is “relevant”
- Heroku and PostgreSQL database backend
- Rust for the implementation language
I ended up revisiting some of those decisions later as well as making a few other ones:
- multi-user capable, but no hosting for other people
- web UI deprioritized given CLI is good enough for a single user
- prioritize better local experience and SQLite support
I quickly settled on a daily email digest that would be coordinated by a program deployed on a server. I didn’t want to rely on my laptop being on as I don’t use it daily. I’ve used Heroku for years for various side projects (e.g. Dancing Together) so I knew what I was getting into :)
For determining what is “relevant,” I chose Google Trends, which tracks the most searched terms on Google over time. This is an area that can be improved in the future (e.g. Twitter trends, topics you are following, etc.), but Google Trends has been good enough for now. At first, I thought about only returning random results, but my partner, Nicole, thought I may enjoy reading timely articles more. That turned out to be a great decision! And the funny thing is, because of false positives, some results are still random, hilariously so.
For personal projects, I try to be as agile as possible to stay motivated, so here’s how I practiced that for Memory Jogger:
- Investigate Google Trends API. There is no official API, but I found https://github.com/pat310/google-trends-api which has several hundred GitHub stars and was easy enough to read. I downloaded it locally and played around with it to figure out the HTTP request/responses and tried them out in Postman. Google Trends will work :)
- Create a Rust program to query Google Trends. At this step, I discovered
Google Trends prepends all HTTP response bodies with
)]}',(probably to make parsing harder for web scrapers?). - Add initial Pocket support. At this point, the program can query Google
Trends and use the search parameter on Pocket’s
retrieveAPI to find relevant items. Yay! The proof-of-concept is complete. - Add initial CI. Now I submit changes via Pull Requests and use GitHub Actions to build the program and run Clippy on it.
- Add frontend and deploy the app to Heroku. I chose actix-web because I had recently used it for another personal project and wanted to explore the actor concurrency paradigm more. The first server program just had a single endpoint to proxy Google Trends requests so I didn’t have to worry about authentication/authorization.
- Improve email output based on experience reading the emails.
- Start a project to improve relevant results. I started syncing Pocket items to the database to enable custom text search. I learned about tf-idf during a college internship and was excited to try it out.
- More email output improvements (add trend link, fallback URL because there isn’t a stable URL to the Pocket Web interface for a given item)
- Decide to prioritize running locally, so start cleaning up codebase (remove web service, remove JS prototype code, simplify codebase)
- Add SQLite support
- Prepare to open source, writing docs and improving UI/UX as I go
- Add integration tests that exercise everything but sending emails
Because I prioritized the substantial part of the application first – syncing Pocket items to the database, implementing text search, sending emails – I had an MVP for myself quickly (within a few days). After using the MVP daily, I prioritized improving search and tweaking the email/command line output, so the app kept getting more useful for me.
For example, at first, I relied on Pocket’s retrieve API which includes a
search parameter. That API is limited to searching item titles and URLs and I
wanted to try other search algorithms to improve results, so I started
downloading saved items to the database. I used simple term-frequency search
on article titles and URLs to mimic the Pocket API. From there, I started
including article excerpts (found by Pocket) to the term frequency searching.
After using it successfully for a few months, I decided against supporting other users. While I was excited to share this project with other people, I didn’t want to be responsible for their Pocket data. With that in mind, I updated my priorities to make Memory Jogger easier to run locally by adding support for SQLite and making the email portion of the app optional (e.g. to use OS notifications).
Notable Implementation Details
- The PostgreSQL and SQLite parts of the codebase “look” very similar, but use
different types. The implementations can probably be converged using generics
to some extent, but they’re not identical. For example, SQLite doesn’t support
a
RETURNINGclause, so you need to perform a load immediately after insertion (in the same transaction), whereas PostgreSQL supports returning the inserted item.
Thank You
Thank you to the contributors to diesel, reqwest, structopt, and actions-rs, which were the major libraries that Memory Jogger relies on. In particular, each one has awesome documentation which has made them simple to integrate.